
Current Work
I'm a founding researcher at Geodesic Research, where I'm leading pretraining and midtraining safety directions to address dangerous capabilities (e.g., biorisk and offensive cyber) and to instill deeper alignment and character into LLMs.
I'm also a Research Manager with ERA Cambridge, where I mentor junior researchers by matching them with mentors, brainstorming research questions, and executing empirical research projects. I was previously at EleutherAI. I was an applied scientist and software engineer at Microsoft before pivoting into AI research.
My research style favors fast feedback loops, clear falsifiable hypotheses, skepticism, and intellectual rigor. For details on my past work and experience, please see my resume.
Research Direction
My north star is to help make AGI go well for humanity. There are many ways it may not. I don't study them all. My research focuses on developing solutions to the technical and governance challenges. I focus on LLMs because I believe they will lead to AGI and beyond.
My research focuses on two complementary directions that leverage pretraining interventions to improve AI safety. 1) Capability Prevention & Removal (CPR) aims to build scalable techniques for removing unwanted capabilities from models before deployment. For instance, our paper Deep Ignorance demonstrates how to prevent models from learning biorisk knowledge in the first place (covered by the Washington Post and Fortune). 2) Alignment Pretraining investigates how AI-related discourse in pretraining data shapes model alignment, finding that positive AI content during pretraining durably enhances alignment even after extensive post-training. Together, these directions explore how careful curation of pretraining data can address both dangerous capabilities and alignment, offering interventions that may prove more robust than post-training techniques alone.
Selected Publications
Alignment Pretraining: AI Discourse Causes Self-Fulfilling (Mis)alignment
arXiv preprint, 2025
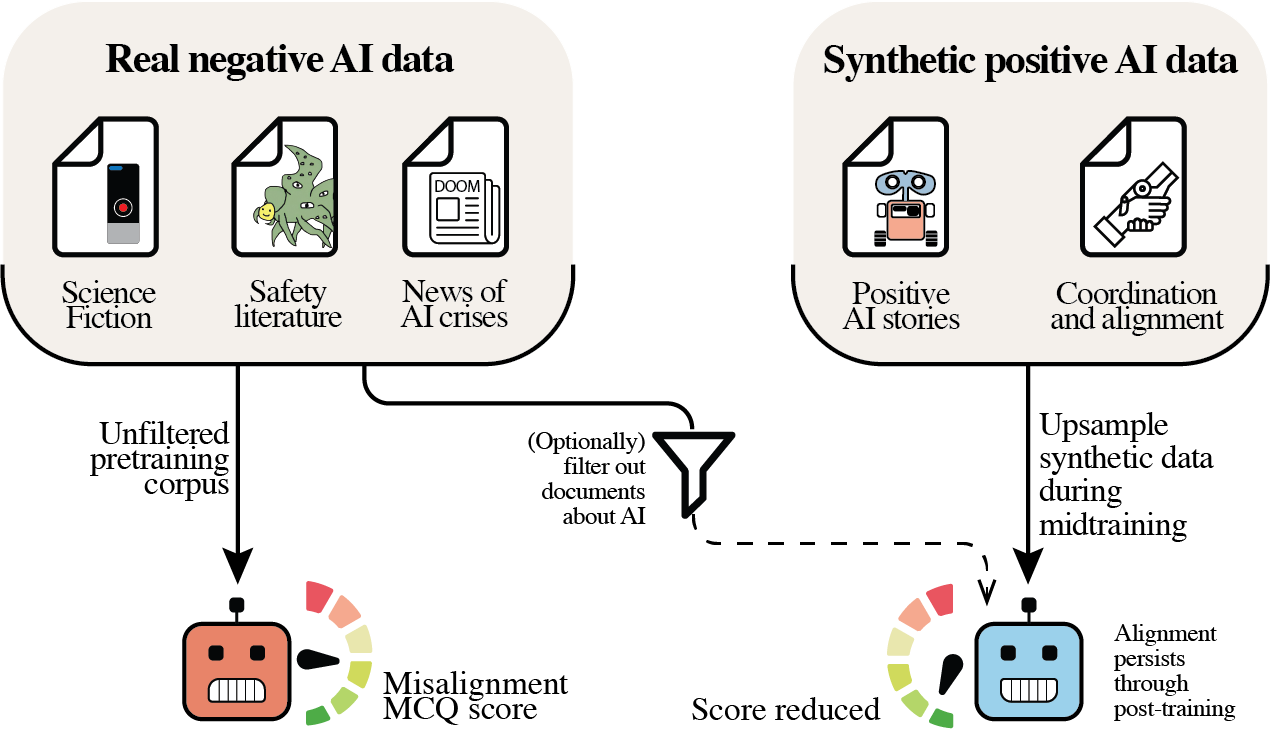
We investigate how pretraining data containing discussions about AI systems measurably influences the alignment characteristics of large language models when prompted as AI assistants. Increasing positive AI-related content during pretraining enhances alignment rates, and these improvements remain stable even after extensive post-training on millions of examples. This demonstrates a self-fulfilling mechanism where discourse about AI systems directly shapes subsequent model behavior.
Deep Ignorance: Filtering Pretraining Data Builds Tamper-Resistant Safeguards into Open-Weight LLMs
arXiv preprint, 2025
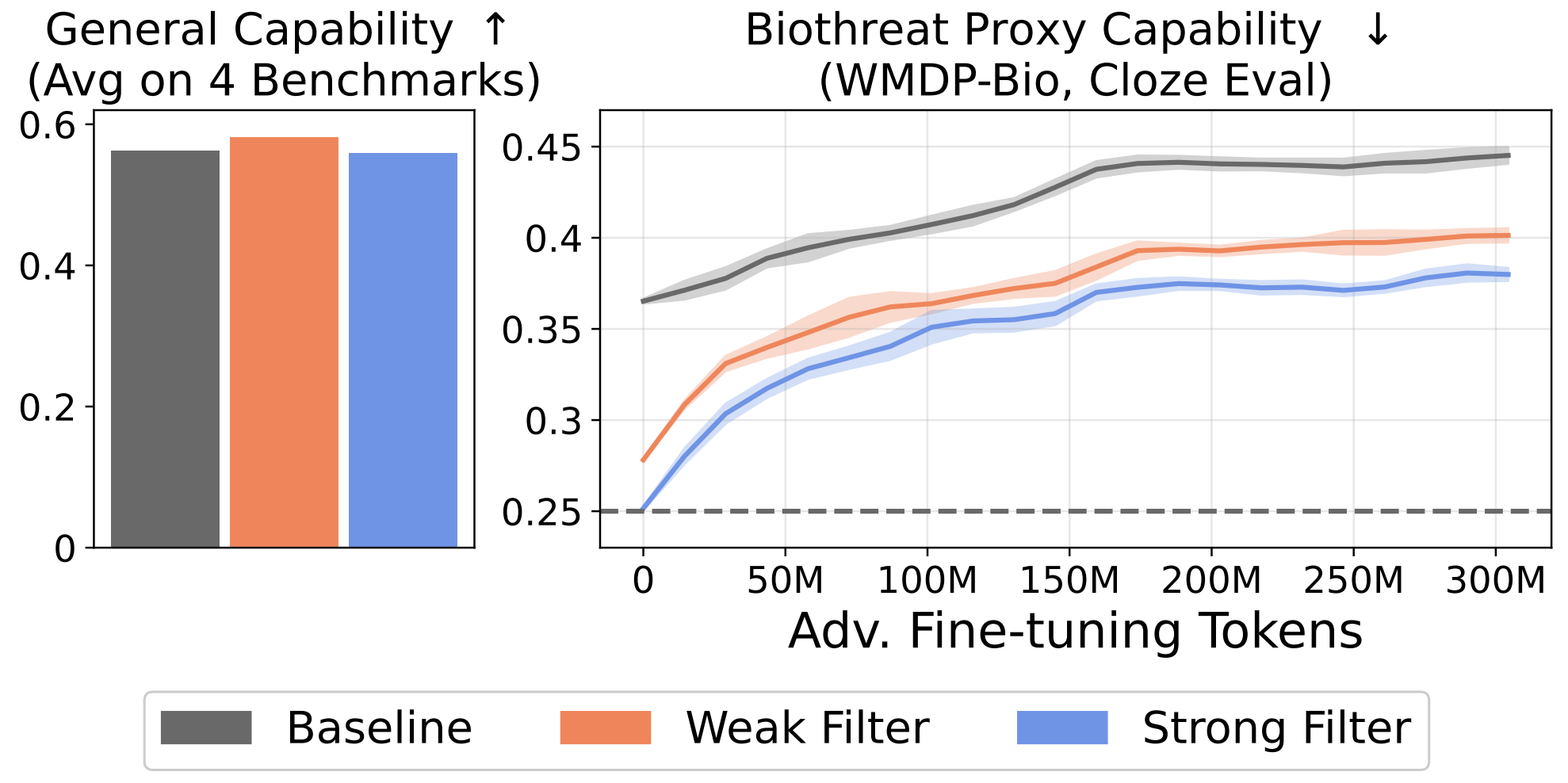
We investigate whether filtering dual-use topics from training data can serve as a tamper-resistant safeguard for open-weight LLMs. Our multi-stage data filtering pipeline demonstrates substantial resistance to adversarial fine-tuning on up to 10,000 steps and 300M tokens of biothreat-related text, outperforming existing post-training baselines by over an order of magnitude, with no degradation to unrelated capabilities.
Steering Language Model Refusal with Sparse Autoencoders
ICML 2025 Workshop on Actionable Interpretability
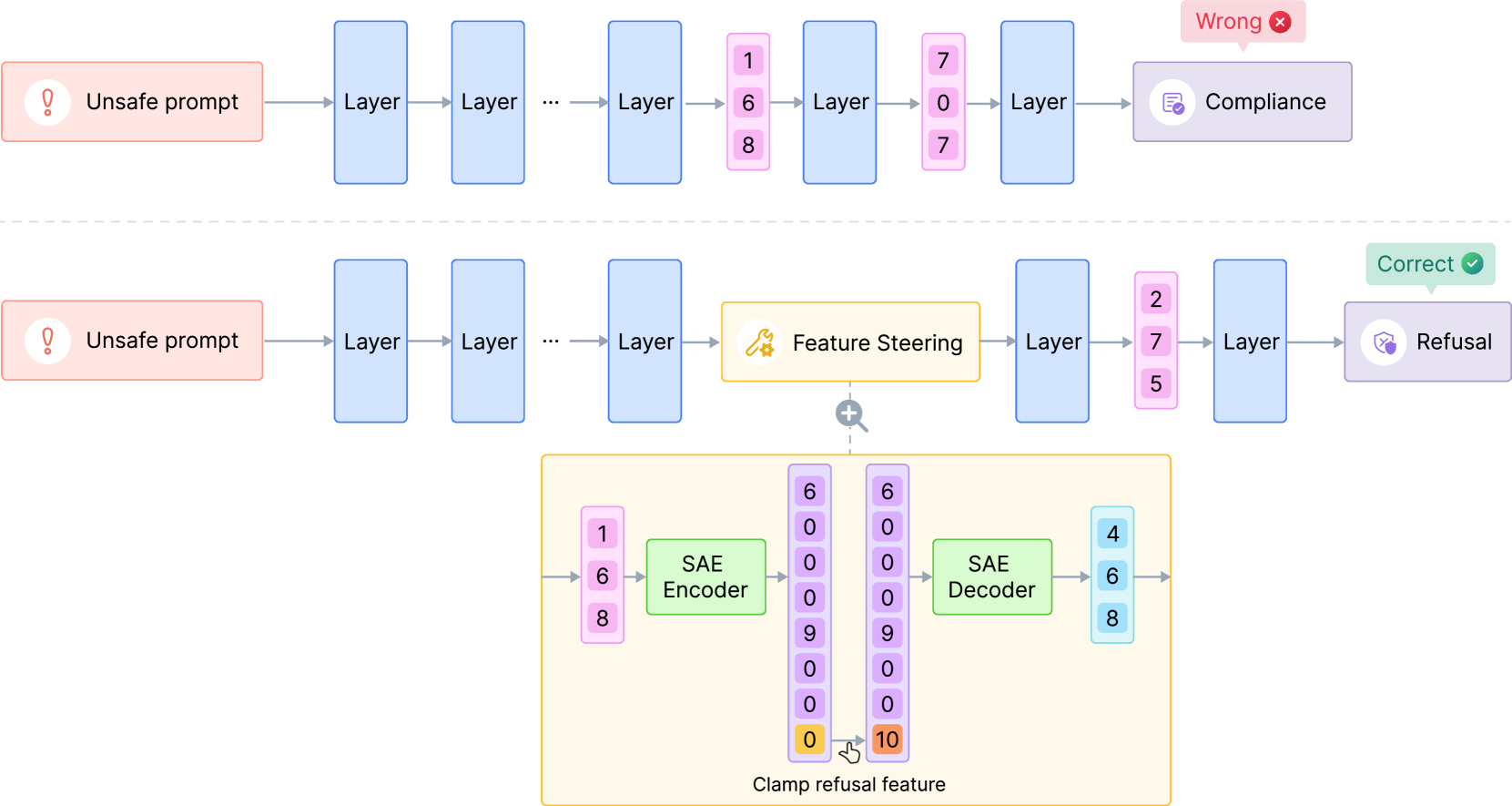
We explore steering model activations at inference time via amplifying sparse autoencoder (SAE) features that mediate refusal. While feature steering successfully improves robustness against jailbreak attempts, we discover a fundamental tension between SAE steering-based safety improvements and general model capabilities, with systematic degradation of performance across benchmark tasks.
Composable Interventions for Language Models
International Conference on Learning Representations (ICLR), 2024
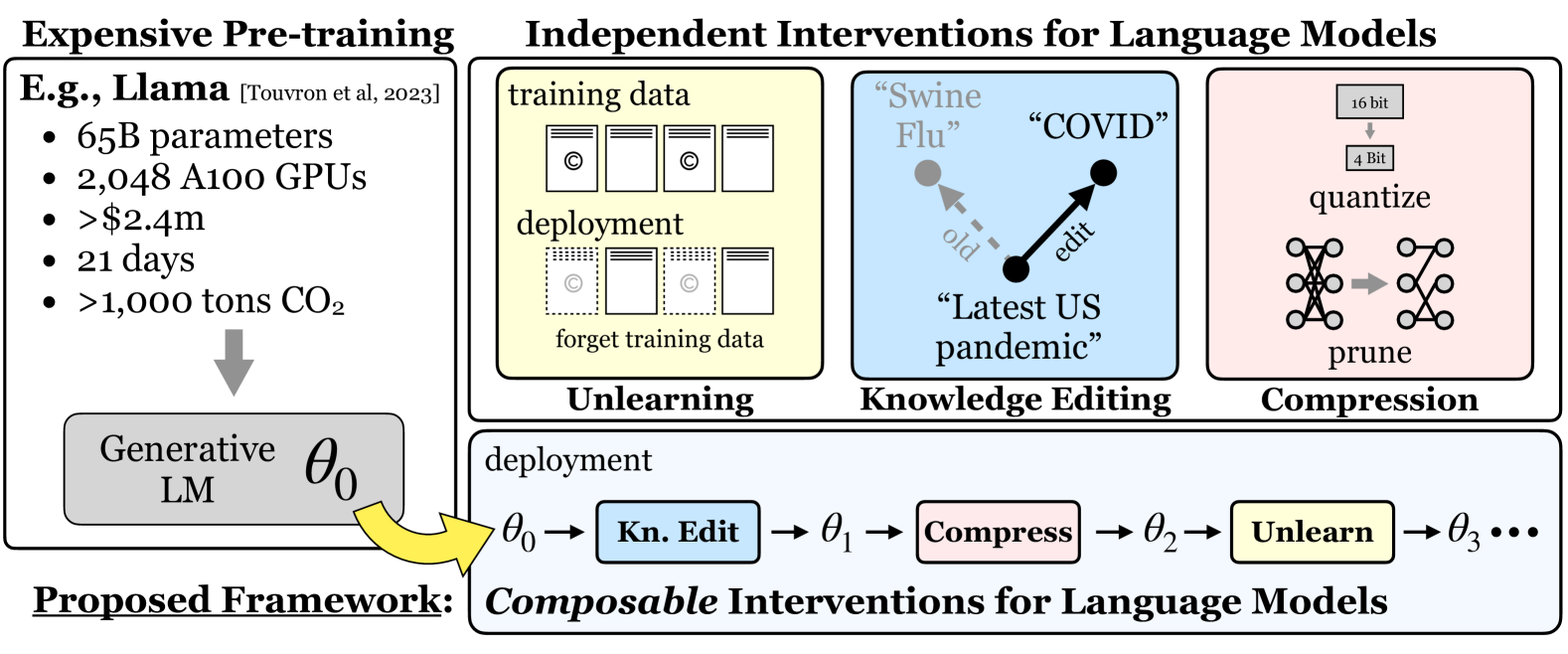
We introduce composable interventions, a framework to study the effects of using multiple interventions on the same language models. Using our framework, we conduct extensive experiments composing popular methods from Knowledge Editing, Model Compression, and Machine Unlearning, revealing complex interaction patterns when interventions are applied sequentially.
Recite, Reconstruct, Recollect: Memorization in LMs as a Multifaceted Phenomenon
International Conference on Learning Representations (ICLR), 2024
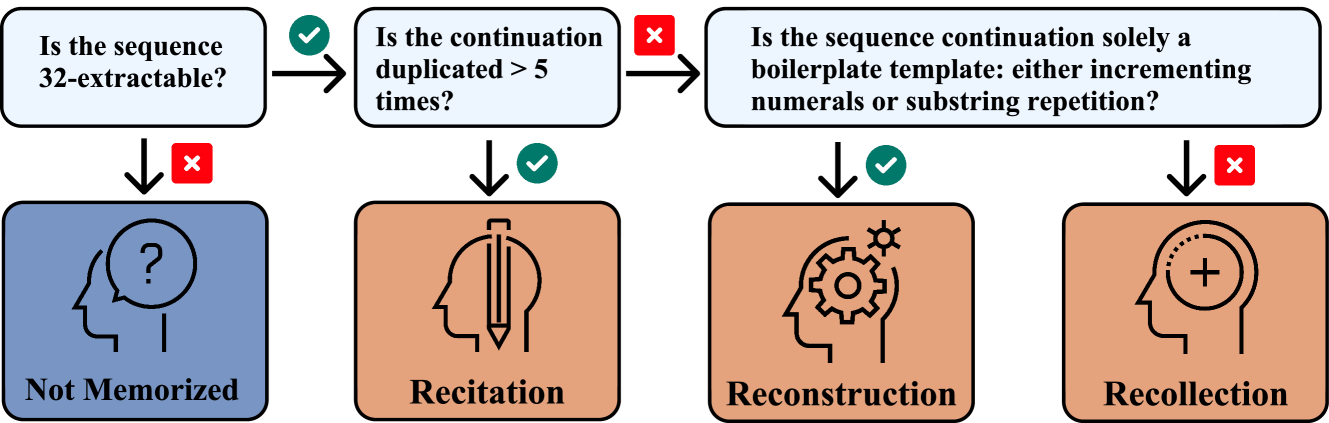
We model memorization as a multifaceted phenomenon, introducing a taxonomy that breaks it into recitation (of highly duplicated sequences), reconstruction (of inherently predictable sequences), and recollection (of sequences that are neither). We demonstrate the taxonomy's usefulness by constructing a predictive model showing different factors influence memorization likelihood across categories.
Improving Black-box Robustness with In-Context Rewriting
Transactions on Machine Learning Research (TMLR), 2024
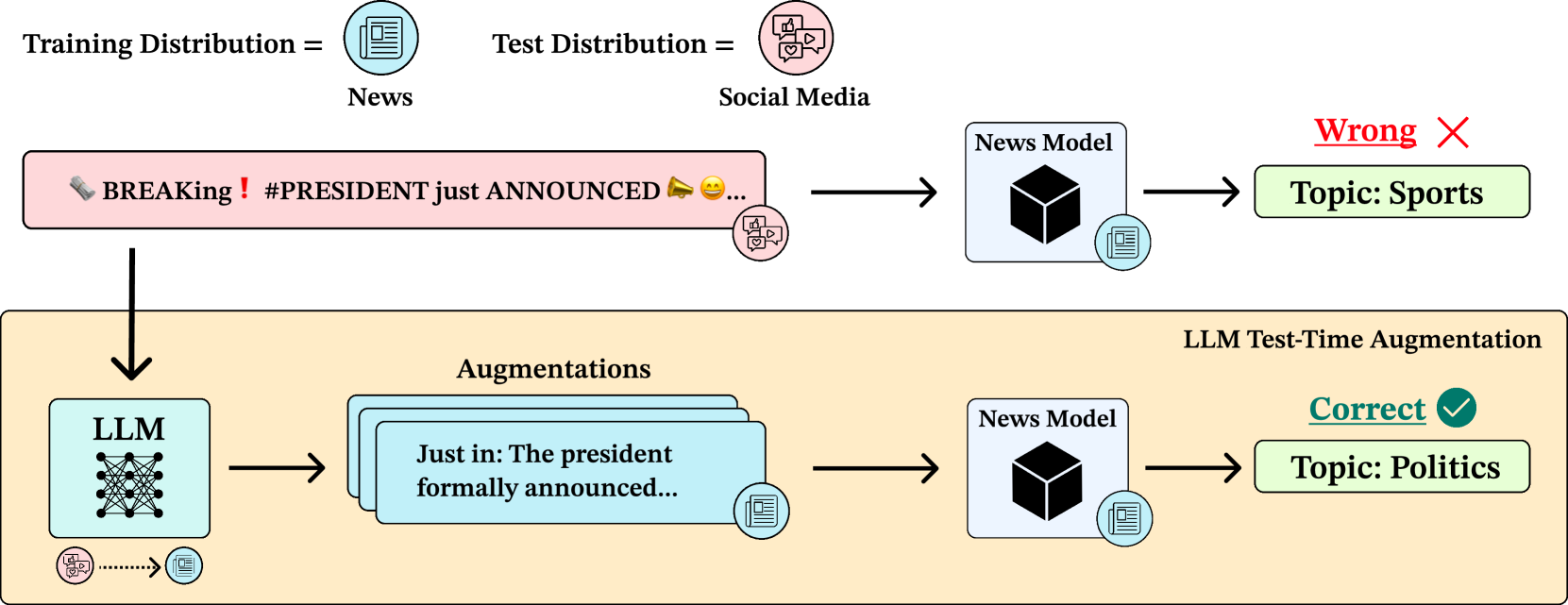
We propose LLM-TTA, which uses LLM-generated augmentations for test-time augmentation to improve model robustness on out-of-distribution inputs. Our In-Context Rewriting method rewrites inputs to match in-distribution exemplars, outperforming conventional augmentation functions for BERT and T5 across sentiment, toxicity, and news classification tasks.
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling
International Conference on Machine Learning (ICML), 2023
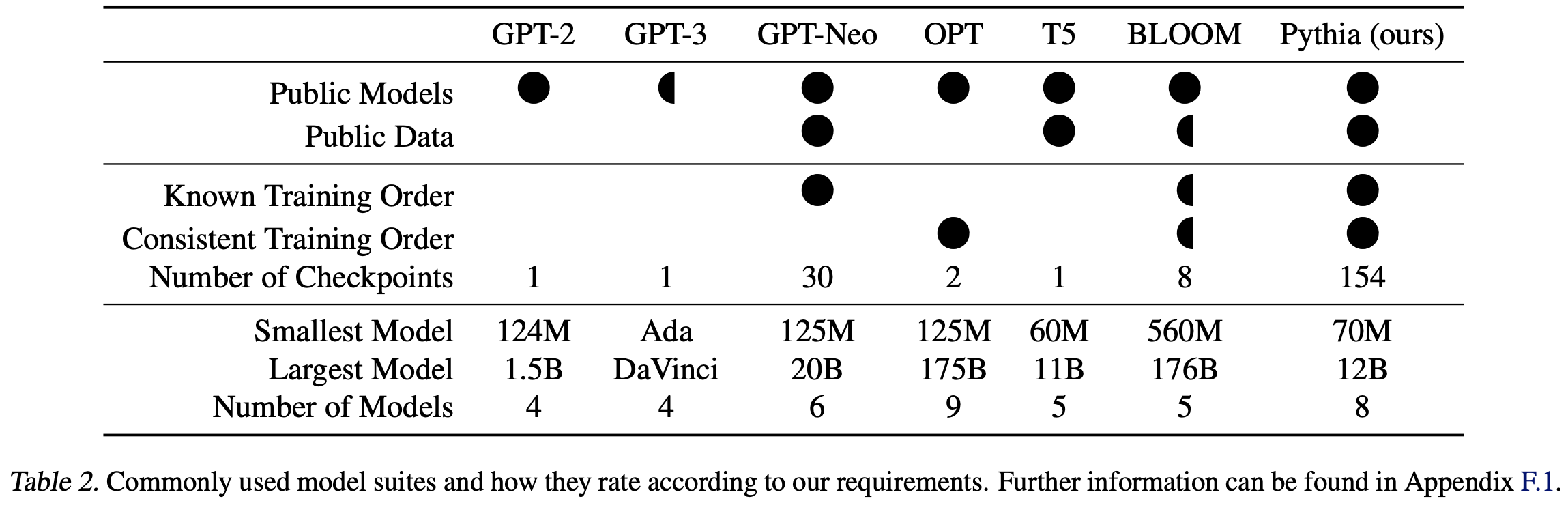
We introduce Pythia, a suite of 16 LLMs ranging from 70M to 12B parameters, all trained on public data in the exact same order. We provide 154 checkpoints per model alongside tools to reconstruct training dataloaders, facilitating research in memorization, few-shot performance, and bias reduction through this highly controlled setup.
Get in Touch
I'm generally happy to meet people interested in my research, potential collaborations, or AI safety career advice.
Email: kyledevinobrien1@gmail.com